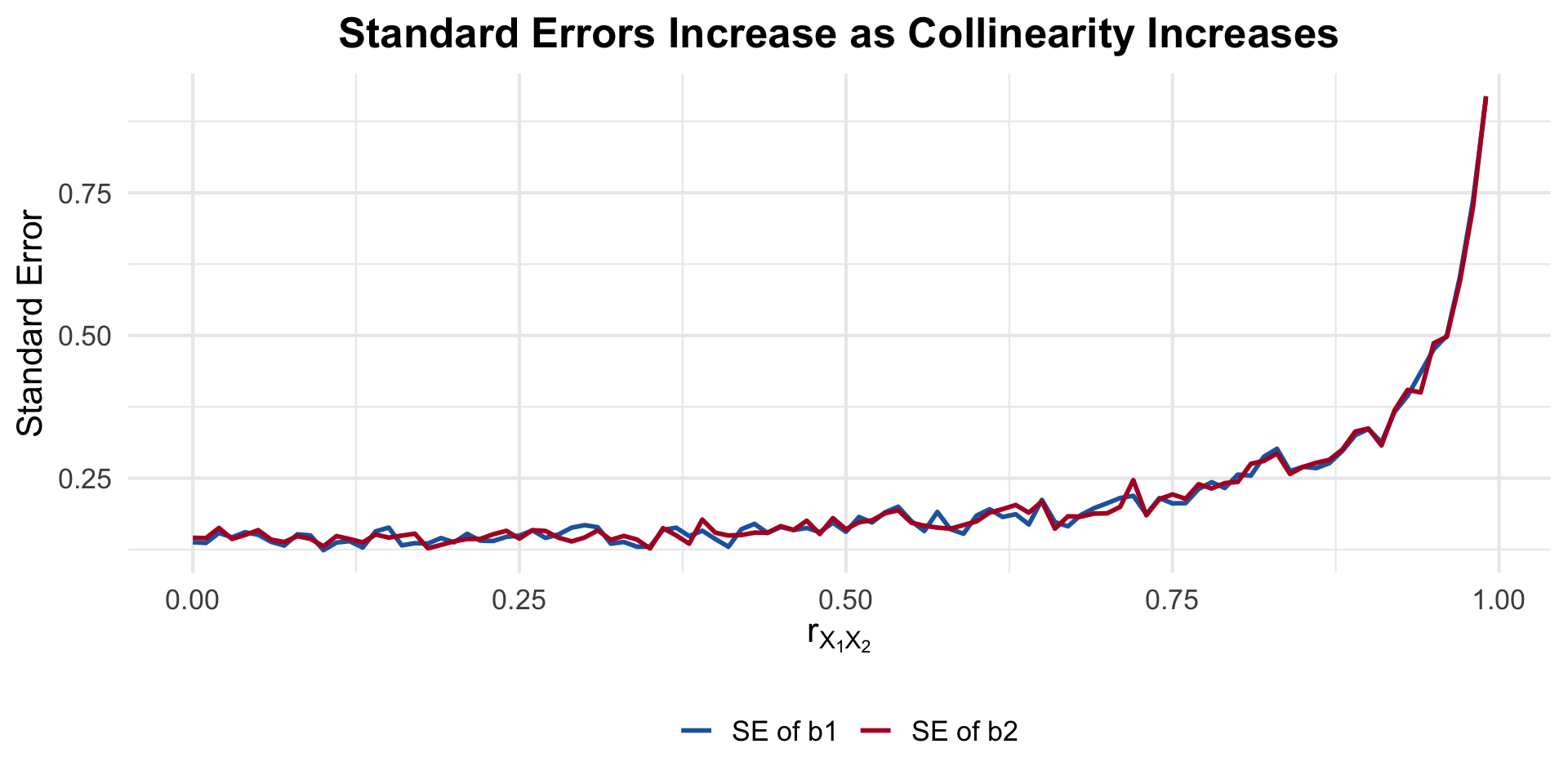
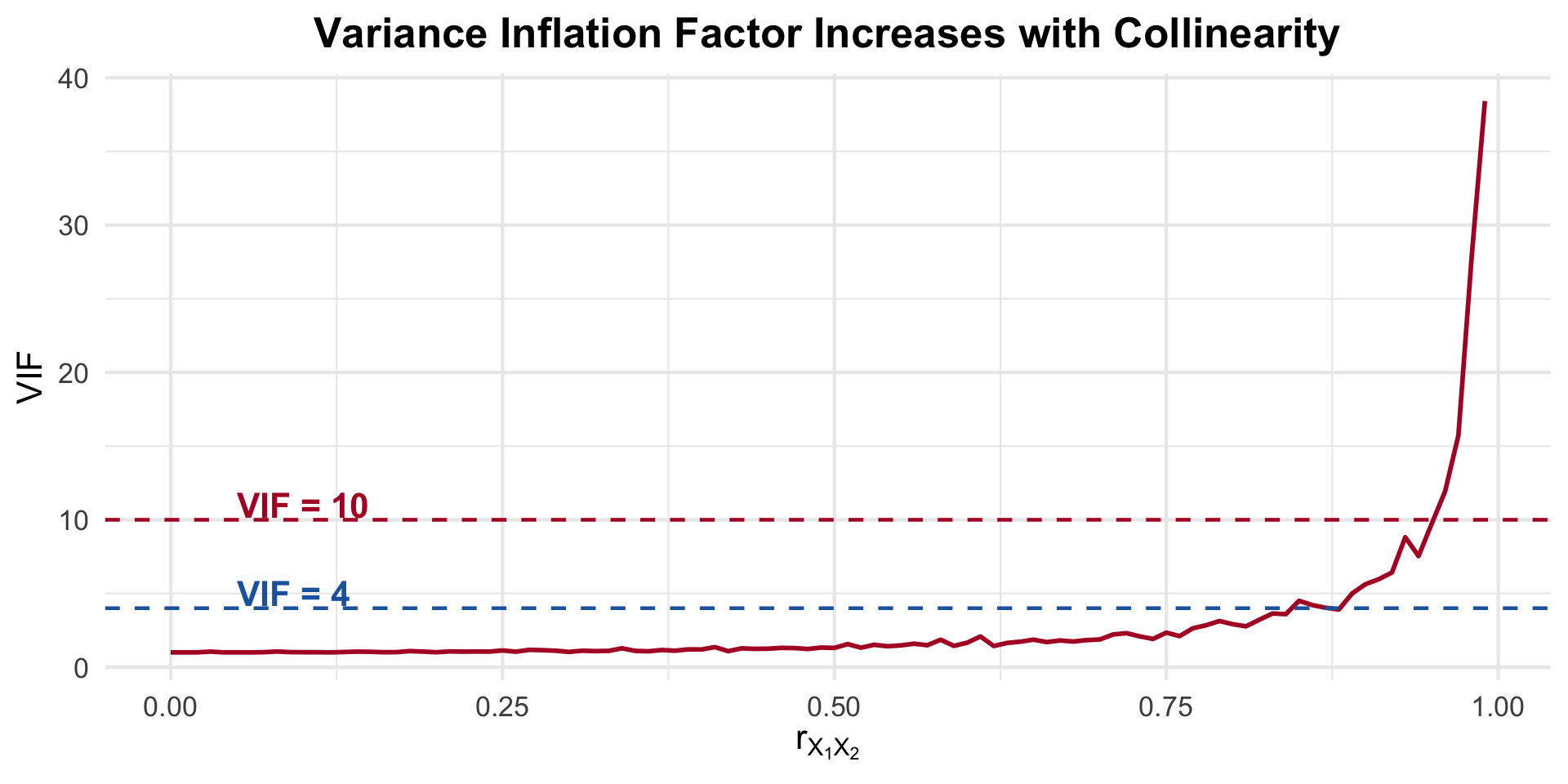
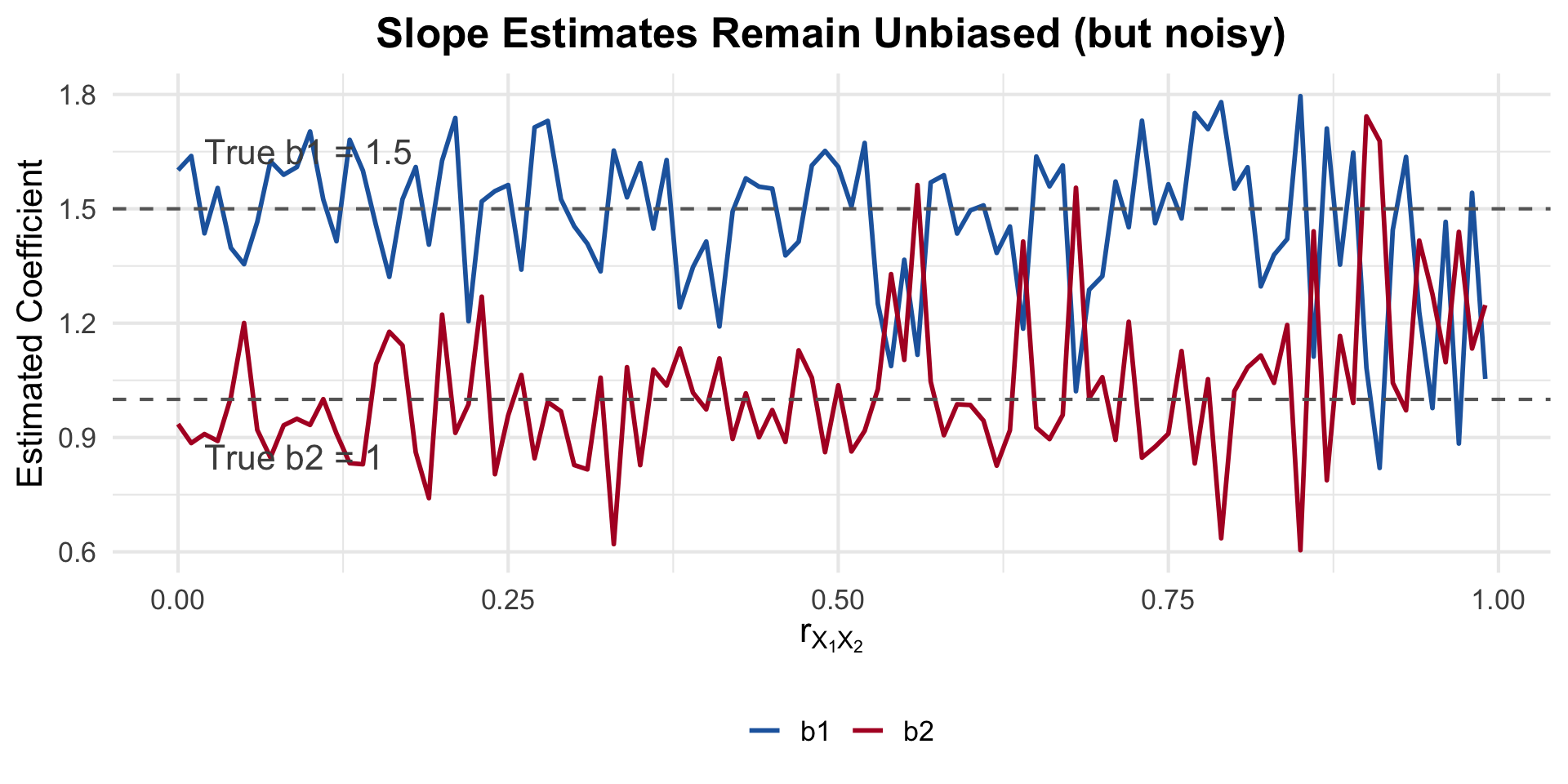
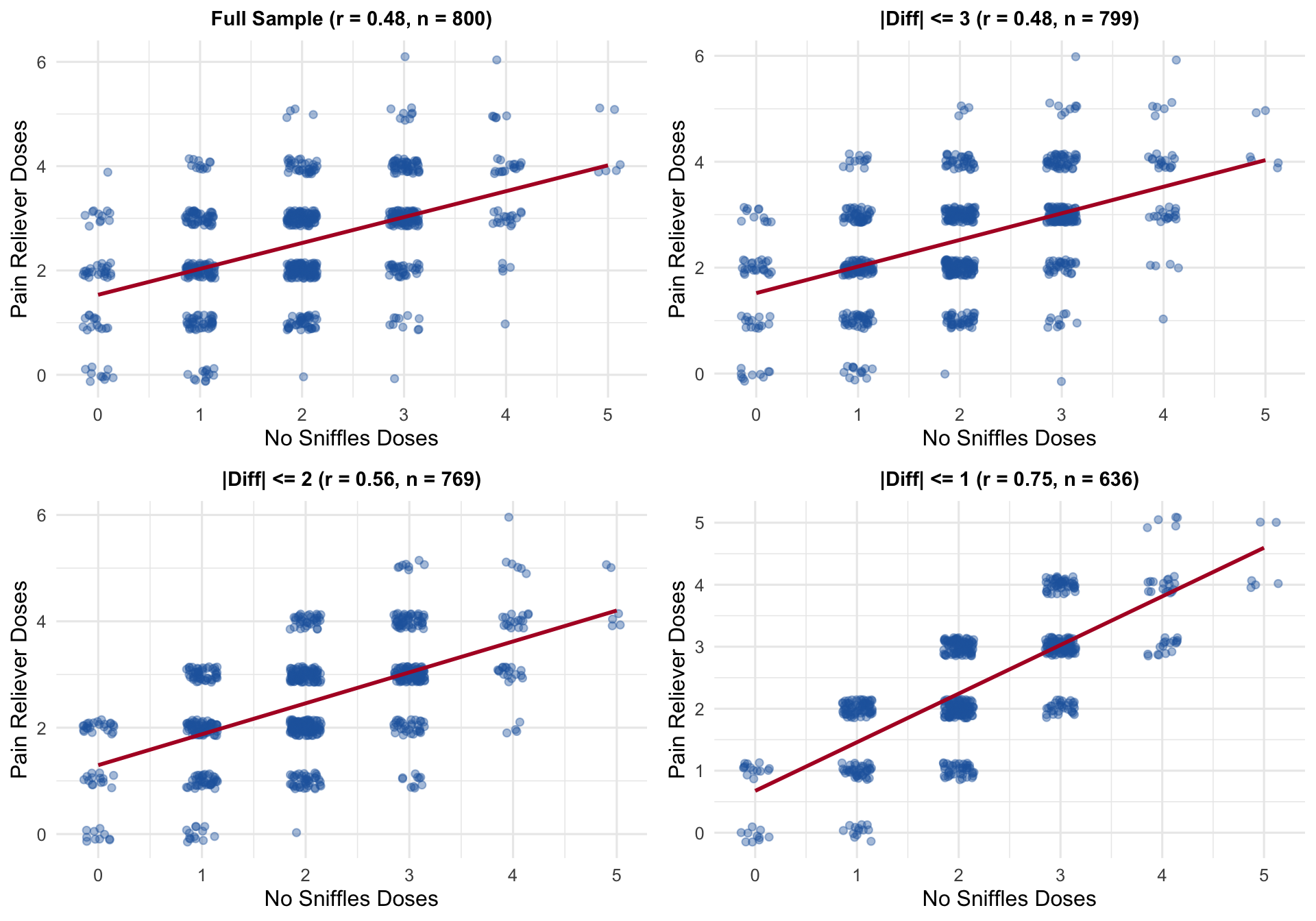
Show code
set.seed(42)
n <- 100
party <- sample(c("Republican", "Independent", "Democrat"), n, replace = TRUE)
auth <- runif(n, 0, 1)
y_trust <- 0.5 + 0.3 * (party == "Republican") - 0.2 * (party == "Democrat") +
0.4 * auth + rnorm(n, 0, 0.3)
d_rep <- as.numeric(party == "Republican")
d_dem <- as.numeric(party == "Democrat")
d_ind <- as.numeric(party == "Independent")
# Include all 3 dummies -- R drops one
cat("All 3 dummies (R drops one):\n")All 3 dummies (R drops one):(Intercept) d_rep d_dem d_ind auth
0.3916643 0.3492268 -0.2866816 NA 0.5729838